
Introductie tot machine learning
WAT IS MACHINE LEARNING?
Dit artikel behandelt de introductie tot machine learning en de direct gerelateerde concepten.
Machine learning is het vakgebied dat computers de mogelijkheid geeft om te leren zonder expliciet geprogrammeerd te zijn. Het is een subset van kunstmatige intelligentie (KI) die zich richt op het gebruik van gegevens en algoritmen om de manier waarop mensen leren te imiteren en waarbij de nauwkeurigheid geleidelijk wordt verbeterd.
Het basisconcept van machine learning betreft het gebruik van statistische leer- en optimalisatiemethoden (link bevindt zich buiten Axisto) waarmee computers datasets kunnen analyseren en identificeren. Machine learning-technieken maken gebruik van datamining om historische trends te identificeren teneinde toekomstige modellen te informeren.
Volgens de University of California, Berkeley, bestaat het typische begeleide machine learning-algoritme uit (ongeveer) drie componenten:
- Een beslissingsproces: Een combinatie van berekeningen of andere stappen die de gegevens opnemen en een ‘gok’ retourneren van het soort patroon in de gegevens dat het algoritme zoekt.
- Een foutfunctie: Een methode om te meten hoe goed de gok was door deze te vergelijken met bekende voorbeelden (indien beschikbaar). Is het besluitvormingsproces goed verlopen? Zo niet, hoe kwantificeert u “hoe erg” de misser was?
- Een update- of optimalisatieproces: waarbij het algoritme naar de misser kijkt en vervolgens de manier, waarop het besluitvormingsproces tot de uiteindelijke beslissing komt, bijwerkt zodat de volgende keer de misser niet zo groot zal zijn.
Machine learning is een belangrijk onderdeel van het groeiende veld van datawetenschappen. Met statistische methoden worden algoritmen getraind om classificaties of voorspellingen te doen, waardoor belangrijke inzichten uit gegevens worden gehaald.
HOE LEERT EEN MACHINE LEARNING ALGORITME?
De technologiefirma Nvidia (link bevindt zich buiten Axisto) onderscheidt vier leermodellen, die worden bepaald door het niveau van menselijke interventie:
- Begeleid leren: Als je onder begeleiding een taak leert, is er iemand aanwezig die beoordeelt of je het juiste antwoord krijgt. Evenzo betekent dit bij begeleid leren dat je een volledige set gelabelde(*) gegevens hebt, terwijl je een algoritme traint.
- Onbegeleid leren: Bij onbegeleid leren krijgt een ‘deep learning’-model een dataset aangereikt zonder expliciete instructies over wat ermee te doen. De trainingsdataset is een verzameling voorbeelden zonder een specifiek gewenst resultaat of correct antwoord. Het neurale netwerk probeert vervolgens automatisch structuur in de gegevens te vinden door nuttige functies te extraheren en de structuur ervan te analyseren.
- Semi-begeleid leren: is voor het grootste deel precies hoe het klinkt: een trainingsdataset met zowel gelabelde als niet-gelabelde data. Deze methode is met name handig wanneer het moeilijk is om relevante kenmerken uit de gegevens te extraheren en het labelen van voorbeelden een tijdrovende taak is voor de experts.
- Versterkend leren: Bij dit soort machine learning proberen AI-algoritmes de optimale manier te vinden om een bepaald doel te bereiken of de prestaties van een specifieke taak te verbeteren. Als het algoritme actie onderneemt die in de richting van het doel gaat, ontvangt het een beloning. Het algemene doel: voorspel de beste volgende stap om de grootste uiteindelijke beloning te verdienen. Om zijn keuzes te maken, vertrouwt het algoritme zowel op lessen uit eerdere feedback als op verkenning van nieuwe tactieken die een grotere beloning kunnen opleveren. Het gaat om een langdurige strategie — net zoals de beste directe zet in een schaakspel je uiteindelijk niet kan helpen om te winnen; het algoritme probeert de cumulatieve beloning te maximaliseren. Het is een iteratief proces: hoe meer feedbackrondes, hoe beter de strategie van het algoritme wordt. Deze techniek is vooral handig voor het trainen van robots, die een reeks beslissingen nemen in taken zoals het besturen van een autonoom voertuig of het beheren van voorraad in een magazijn.
* Volledig gelabeld betekent dat elk voorbeeld in de trainingsdataset is voorzien is van het antwoord dat het algoritme op zichzelf zou moeten produceren. Dus een gelabelde dataset van bloemenafbeeldingen zou het model vertellen welke foto’s rozen, madeliefjes en narcissen waren. Wanneer een nieuwe afbeelding wordt getoond, vergelijkt het model deze met de trainingsvoorbeelden om het juiste label te voorspellen.
In alle vier de leermodellen leert het algoritme van datasets met menselijke regels of kennis.
Bij het navigatie van het domein van kunstmatige intelligentie komt niet alleen de term machine learning langs, maar ook deep learning (DL) en neurale netwerken (artificiële neurale netwerken – ANN). Kunstmatige intelligentie en machine learning worden door elkaar heen gebruikt, netals machine learning en deep learning. Maar in feite zijn ze een subset van een subset zoals gevisualiseerd in figuur 1.
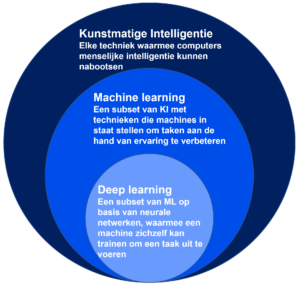
Daarom worden hieronder ook deep learning en kunstmatige neurale netwerken kort toegelicht.
HET VERSCHIL TUSSEN MACHINE LEARNING EN DEEP LEARNING IS IN DE MANIER WAAROP EEN ALGORITME LEERT
In tegenstelling tot machine learning, vereist deep learning geen menselijke tussenkomst om gegevens te verwerken. Deep learning automatiseert een groot deel van het functie-extractie proces, waardoor een deel van de handmatige menselijke interventie, wordt geëlimineerd en het gebruik van grotere datasets mogelijk wordt. “Non-deep” machine learning is voor het leren in meer of mindere mate afhankelijk van menselijk ingrijpen. Menselijke experts bepalen de reeks functies om de verschillen in de gegevensinvoer te begrijpen, waarvoor meestal meer gestructureerde gegevens nodig zijn om te leren. “Deep” machine learning kan gebruikmaken van gelabelde datasets, ook wel begeleid leren genoemd, om het algoritme te informeren, maar het vereist niet per se een gelabelde dataset. Het kan ook ongestructureerde gegevens in onbewerkte vorm verwerken (bijv. tekst en afbeeldingen) en het kan automatisch de reeks functies bepalen die verschillende categorieën van gegevens van elkaar onderscheiden.
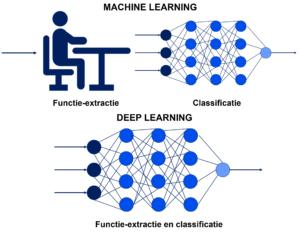
Deep learning gebruikt meerdere lagen om geleidelijk hogere niveaus van functies uit de onbewerkte invoer te extraheren. Bij beeldverwerking kunnen lagere lagen bijvoorbeeld randen identificeren, terwijl hogere lagen de concepten kunnen identificeren die relevant zijn voor een mens, zoals cijfers of letters of gezichten.
Bij deep learning leert elke laag zijn invoergegevens om te zetten in een iets meer abstracte en samengestelde weergave. In een toepassing voor beeldherkenning kan de onbewerkte invoer een matrix van pixels zijn. De eerste representatieve laag kan de pixels abstraheren en randen coderen. De tweede laag kan rangschikkingen van randen samenstellen en coderen en de derde laag kan een neus en ogen coderen. De vierde laag kan herkennen dat de afbeelding een gezicht bevat. Belangrijk is dat een deep learning proces zelfstandig kan leren welke kenmerken op welk niveau optimaal kunnen worden geplaatst. Dit elimineert de noodzaak voor handmatig ingrijpen niet volledig; verschillende aantallen lagen en laagafmetingen kunnen bijvoorbeeld verschillende gradaties van abstractie opleveren.
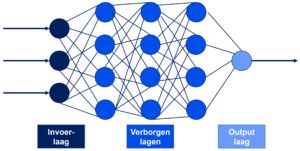
Het woord “deep” in “deep learning” verwijst naar het aantal lagen waardoor de data wordt getransformeerd, zie figuur 3.
NEURALE NETWERKEN
Kunstmatige neurale netwerken leren op meerdere lagen van details of representaties van gegevens. Door deze verschillende lagen gaat informatie van parameters op een laag niveau naar parameters op een hoger niveau. Deze verschillende niveaus corresponderen met verschillende niveaus van data-abstractie, wat leidt tot leren en herkennen.
Een ANN is gebaseerd op een verzameling van verbonden eenheden die kunstmatige neuronen worden genoemd (analoog aan biologische neuronen in een biologisch brein). Elke verbinding (synaps) tussen neuronen kan een signaal naar een ander neuron sturen. Het ontvangende (post-synaptische) neuron kan het signaal/de signalen verwerken en vervolgens de stroom-afwaartse neuronen die ermee verbonden zijn, signaleren. Neuronen kunnen een toestand hebben, over het algemeen weergegeven door reële getallen, meestal tussen 0 en 1. Neuronen en synapsen kunnen ook een gewicht hebben dat varieert naarmate het leren vordert, wat de sterkte van het signaal dat het stroomafwaarts verzendt, kan vergroten of verkleinen. Meestal zijn neuronen georganiseerd in lagen. Verschillende lagen kunnen verschillende soorten transformaties uitvoeren op hun invoer. Signalen gaan van de eerste (invoer) naar de laatste (uitvoer) laag, mogelijk na meerdere keren door de lagen heen te zijn gegaan.
TOEPASSINGEN VAN MACHINE LEARNING
Er zijn veel toepassingen voor machine learning; het is een van de drie belangrijkste elementen van Intelligente Automatisering en een autonoom operating model binnen Industrie 4.0. Machine Learning-applicaties kunnen tekst lezen en bepalen of de persoon die het heeft geschreven een klacht indient of feliciteert. Ze kunnen ook naar een muziekstuk luisteren, beslissen of het iemand blij of verdrietig zal maken, en andere muziekstukken zoeken die bij de stemming passen. In sommige gevallen kunnen ze zelfs hun eigen muziek componeren waarin dezelfde thema’s tot uitdrukking komen, of waarvan ze weten dat ze gewaardeerd zullen worden door de fans van het originele stuk.
Neurale netwerken worden gebruikt voor een verscheidenheid aan taken, waaronder computervisie, spraakherkenning, machinevertaling, filtering van sociale netwerken, het spelen van bord- en videogames en medische diagnose. Vanaf 2017 hebben neurale netwerken doorgaans een paar duizend tot een paar miljoen eenheden en miljoenen verbindingen. Ondanks dat dit aantal enkele ordes van grootte kleiner is dan het aantal neuronen in een menselijk brein, kunnen deze netwerken veel taken uitvoeren op een niveau dat verder gaat dan dat van mensen (bijvoorbeeld gezichten herkennen en “Go” spelen).

Articles


